
Conversational UX for Dummies
How to design voice interfaces that make people go "Wow!"
- 🗓️ Date:
- ⏱️ Time to read:
Table of Contents
As part of my scholarship for DesignUp Bangalore, 2018.
Siri. Amazon Alexa. Google Home.
These are the names that come to mind when we think of “Smart Speakers”. Voice Assistants that can tell you the weather, book an Uber, order food from your favourite restaurant — and take it up a notch by reviewing your food in Gordon Ramsey style.
Or if you’re like me who’s trying to find the meaning of life, just ask Google.
On December 14 2018, Amazon Alexa discovered a rather unusual user amongst the usual ones. Unlike the others, this one didn’t even know that it was a user. It could talk like a human, but it wasn’t a human at all.

Meet Rocco the Parrot
The Smart Device had met its match in the form of a Smart Bird. Over the next few days, this African Grey had repeatedly ordered treats for itself — including strawberries, watermelon, raisins, broccoli and ice cream.
But it didn’t stop there. It later also placed orders for a kite, light bulbs and even a kettle. And when bored, it tells Alexa to also play its favourite tunes to groove to. This bird is could be more tech-savvy than your average grandma if you ask me.

But I digress. Speaking of your grandma, let’s ignore the parrot for a minute and talk about humans instead —
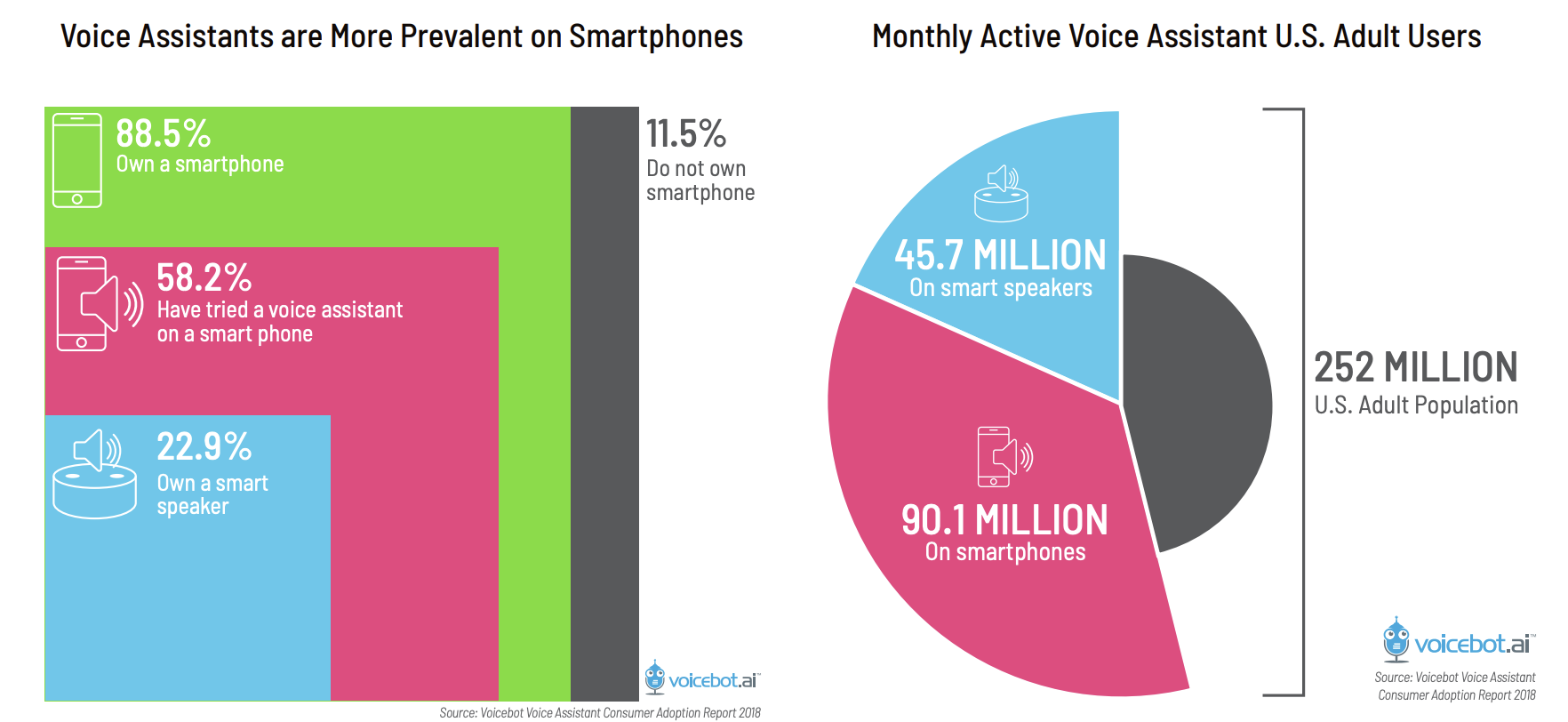
As of September 2018, almost 60 million out of 252 million of the US population owned a smart speaker. By the end of 2018, the smart speaker base has likely crossed 100 million, with China driving over half of the global smart speaker growth.
Speech technologies have applications outside the confines of your homes too — in call centres and IVRs, in automobiles, in education, to even hospitals and medical robotics. But what makes them so special, and how did they start to become so widespread in the first place? Let’s take a quick history lesson to find out.
A brief history of speech recording, synthesis and recognition
Before computers and digital revolution came to be, people throughout history have tried building devices that can record and duplicate human speech. Although early theories on how to build such a device existed in the late medieval period, no one really came close to building one.
In the early modern era, the invention of the Brazen Head had caught people’s curiosity. This mechanical head had the ability to answer correctly “Yes” or “No” type questions. The public never really knew how and usually attributed this to magic or wizardry!
Then in 1769, Wolfgang von Kempelen, an Austro-Hungarian inventor began the process of building the world’s first ever mechanical speech machine, whose design was based on the human vocal anatomy. His third design was completely capable of speaking complete phrases in French, Italian and English. It was still challenging because it needed a skilled human operator!
But wait, this wasn’t sufficiently advanced yet. The true progress of speech recognition came after almost a century of research and breakthroughs by hundreds of researchers, scientists who worked on the areas of electronics, computing, linguistics and audio processing. Let’s take a tour at some of the most important milestones achieved in the last 200 years —
The late 1800s — speech synthesis
In 1877, Thomas Edison invented the world’s first ever machine that could both record and reproduce sound, called the Phonograph. Sounds could be recorded as physical deviations engraved on a cylinder. To re-create the sound, the surface of the cylinder had to be rotated, while a needle-like stylus traced the engravings on it and produce vibrations, very faintly reproducing the sound.
Alexander Bell, together with his team at Volta Laboratory, made several improvements to the original phonograph (using wax instead of tinfoil, and later replacing the cylinder with a disc) and made what is known as the Graphophone, or Gramaphone.
“There are more things in heaven and earth, Horatio, than are dreamed of in your philosophy. I am a Graphophone and my mother was a phonograph.” — earliest recording of the graphophone at the Volta Labs
Later, Graphophone’s trademark rights were acquired by several other companies before finally getting acquired by Columbia Phonograph Company. Sold as “The Dictaphone”, it was meant to be used as a dictation machine meant to record dictation of notes and letters for a secretary and replace stenographers at offices. Due to the low quality of playback, music wasn’t considered a major application at that time.

Although at first focusing only on sales and services, Columbia started selling disc records of early artists as well, then entering into the broadcasting business, eventually becoming what we know today as Columbia Records. Artists who have recorded for Columbia include AC/DC, Pink Floyd, George Michael, Harry Styles and many others!
From 1928 — Towards speech recognition
Alexander Bell had laid the early foundations of what later became Bell Labs. Bell Labs made plenty of breakthroughs in the scientific and sound fields, including —
- The Voder, one of the earliest devices to electronically reproduce human speech. (around this time, researchers in Germany had invented the magnetic tape recorder). It was demonstrated in Golden Gate International Exposition in San Francisco in 1938.
- In 1952, The Audrey (short for Automatic Digital Recognition) — one of the earliest speech recognition device, could recognize phonemes and digits.
Meanwhile, researchers at IBM started to make breakthroughs of their own —
- The Shoebox, a machine demonstrated during the year 1962 that could understand up to 16 words and 10 digits spoken in English. This device could do simple math calculations via voice commands.
- In 1971, IBM invented the Automatic Call Identification system, that allowed Engineers anywhere in the US to talk to and receive “spoken” answers from a computer in Raleigh, NC. It was one of the earliest speech recognition systems that could operate over telephonic lines and understand different voices and accents.
- In the early 1980s, IBM began work on the Tangora, a machine that would be able to recognize 20,000 spoken words.
DARPA
Around the same time, The United States Department of Defence created The Defense Advanced Research Projects Agency during the time of the Space Race, shortly after World War 2.
- DARPA began to fund research and development of many non-military fields, many of which directly or indirectly influenced speech recognition.
- One of them was the DARPA Speech Understanding Research (SUR) program, a project which lasted 5 years and led to the creation of the Harpy by Carnegie Mellon. Harpy had the vocabulary of a three year old and was capable of understanding 1,011 words. Unlike its predecessors, it could recognise entire sentences.
From early 2000s till now — Towards Speech Prediction
Most speech recognition advancements in the last decade were still based on template matching. The operator (or user) had to speak very slowly, using clear words, avoid homonyms, and have no background noise in the surroundings for the the machine to recognize their voice.
With further strides made in computing, and hidden markow models, speech recognition became even more accurate — and speech prediction was starting to become a reality.
This decade saw a wide-spread adoption of smart-phones. There was a renewed interest in deep learning. and speech recognition systems had more data to train on than ever before. With neural-network architectures like RNNs and LSTMs and transfer learning, large-scale automatic speech recognition was becoming more easier to deal with.
- In 2002, Microsoft brought speech recognition into their Office products.
- 2006, The National Security Agency started using speech recognition to isolate keywords when analyzing recorded conversations
- Next, Google brought voice search in the iPhone in 2008.
- Then came Siri from Apple, in 2011. The first most widely used digital assistant that could understand simple phrases, and perform the appropriate action on the iPhone.
- 2014, Microsoft releases Cortana, a digital assistant similar to Siri.
- Finally, late 2014, Amazon releases Echo — a voice controlled speaker powered by Alexa.
Finally, we arrive at today.
Any sufficiently advanced form of technology is indistinguishable from magic.
Remember Rocco the parrot from earlier? With the latest advances in Deep Learning, voice based assistants have become more precise than ever — with accuracy being on par with humans now. So while today we use it barely, we’ll be using them more often in the next few years.
Looks like we’ll be having conversations with our gadgets more often than real people. Isn’t that just awesome or what?!
And just like any other technology out there, adoption of speech technology have their own set of challenges. And these challenges are not just prevalent in your everyday smart-phone or smart-speaker.
People want these technologies to understand them better and communicate better more than anything else. Or in other words, a better user experience.
It would be nice if my Google Home proactively told me things I should know before leaving the house.
— Ryan Hoover (@rrhoover) December 21, 2018
E.g. “It's raining right now. Grab an umbrella!"
Basically I want Google Home to be more like my mom. ❤️ @shreebobnish.
During October at DesignUp Bangalore, we had a masterclass on Conversational User Interfaces, by Bruce Balentine — author of It’s Better to be a Good Machine than a Bad Person. Without further ado, I’ll dive in more detail on speech systems, and also share with you the lessons that I learned from the workshop.
Before we start to think about user experience, it is necessary to understand the medium of interaction in more detail.
When is Speech Sexy?
Let’s begin by first understanding what is speech good for —
Scenario #1: When your hands are busy or messy
For example, when you’re cooking in the kitchen and you need to follow instructions from a recipe. Your hands are stained and so you don’t want to touch your mobile screen.
Or when you’re navigating your bike in Bangalore’s tough streets — you definitely don’t want to take your hands off the handles!
Scenario #2: When your eyes are busy or unavailable.
Distracted driving is one of the leading causes of vehicle accidents. Answering a text takes away your attention for about five seconds.
So if you’re traveling at 80 kms/hour, that’s enough time to travel the length of a football field. This is definitely a scenario when speech interfaces will come in handy.
Scenario #3: When there’s no light or when you’re at a distance.
Home automation is a big application. Imagine instead of fumbling in the dark to reach for the light switch or getting up from your comfy sofa for the remote, you just spoke aloud “Hey Google, turn on
Scenario #4: When there is specific information that needs to be accessed easily, immediately — to you or a bunch of people.
A speech interface can easily remind you of your shopping list. Railway and airport announcements are of this nature, and they can be communicated to a large number of people.

Shortcomings of Speech
Despite their numerous advantages, speech based applications are also prone to some drawbacks —
Drawback #1: Often uncertain and ambiguous
Although speech recognition systems have vastly improved on accuracy in recent years, they are still error-prone. The most famous one last year being Amazon Alexa freaking out its users by laughing at inappropriate moments.
Even though these errors can be fairly harmless, it can be a big problem in a different setting. The International Journal of Medical Informatics did a research study where emergency room doctors used speech-to-text software at a busy hospital, that treated approximately 42,000 visitors per year. Mis-translations were as high as 15%, and this is enough to affect patient treatment and care.
Drawback #2: Persistence of Information
On a screen, information can be visible at all times — as long as you don’t switch to another screen. But with a speech interface, it only exists as long as it is spoken. Or in other words — it exists only on the dimension of time, and doesn’t have the spatial advantages as that of other interfaces.
So for example — tasks like airline reservations or complex financial transactions can be bad fits for speech, because they usually have intermediate steps that involve comparison and reflection on what you have done.
Drawback #3: Lack of privacy
Since voice can be heard by other people, the usage is often limited to the confines of your home. Although this problem can be mitigated to some extent by using a pair headphones.
Drawback #4: Can be slow
Hearing information can often be slower when compared to just reading it on a screen. It can get even slower when there are errors.
Why is Speech Weird and Counter-intuitive?
- Because we still don’t it understand fully yet. Language is an evolved biological skill, and is still constantly evolving. What makes the human brain uniquely adopted to language is still somewhat unclear. This in turn, makes it difficult to design and train speech systems.
- People by nature having different accents and unique styles of conversations makes speech interaction more ambiguous and uncertain than any other medium.
- Almost all errors look like “accuracy errors” — even if the error might be in the translation part, or the hardware part, or if introduced via noise in the environment.
- And most importantly, speech isn’t persistent — so you often will need to rely on your keen sense of hearing and your brain for retaining and recalling information.
Design Thinking often involves using the strengths and finding ways to work around the weaknesses.
Now that we know more about speech and its nature, let’s dive into few of the most common use-cases for speech technologies and examine them in close detail —
User Experience Use Case: Public Announcements
If you announce this announcement then you’d have announced that this announcement is not worth announcing. 😛
Here’s an example from Bruce’s workshop of a flight delay announcement. For a better observation, you can try pasting it on Google Translate and listen to it instead of reading —
Attention, passengers flying on Air Indigo Flight Number 6E571,
departing Chennai at 15:15 today and arriving at Guwahati at 17:45.
The flight is delayed. New departure time is 15:45 with an arrival time of 18:13.
Boarding will commence at 14:45 at gate number 3.
Please standby for any additional announcements. We apologize for any inconvenience.
Surely you have been in a scenario very similar to this one. In a few seconds, you’d be struggling to remember the details. Was the boarding time 14:45 or 15:45? And did the announcement say 18:13 or 18:30?
Unnecessary verbs, propositions, conjunctions can come in the way of us absorbing information effectively. Making something verbose does not equate to it being better. So what happens when you remove these words?
Attention, passengers flying — Air Indigo Flight Number 6E571, departing Chennai — 15:15 today — arriving — Guwahati — 17:45.
The flight — delayed. New departure time — 15:45 — arrival time — 18:13.
Boarding — commence — 14:45 — gate number 3.
Please standby — additional announcements.
We apologize — inconvenience.
Let’s try removing some more superfluous information so that we hear only stuff that’s relevant for us —
Attention, passengers flying Air Indigo Flight Number 6E571.
The flight — delayed. New departure time 15:45 arrival time 18:13.
Boarding commence 14:45 gate number 3.
Definitely much shorter now. We can do with more re-structuring and organizing. Remember — good design like anything else, is an iterative process!
Air Indigo 571 is delayed.
Departure time: 15:45.
Arrival time: 18:13.
Boarding commence: 14:45, gate number 3.
Finally, we have all the right words!
But remember, you’re still dealing with humans in an airport! They might be chit-chatting with their kids, taking selfies, or listening to music for all you know. It takes time for them to garner and pay attention to what you’re saying.
“The right word may be effective, but no word was ever as effective as a rightly timed pause.” — Mark Twain
Here is our final transcript —
Air Indigo 5-7-1.
This is a delay announcement for...
Air Indigo... 6E 5-7-1.
Boarding time... 15:15. Gate number... 3.
Departure time... 15:45.
Arrival Guwahati... 18:13.
Now try hearing the same on Google Translate!
General guidelines
- The numbers are read one digit at a time whenever possible. In this case, the flight number should be read as five-seven-one, and not five-seventy-one or five-hundred-seventy-one.
- Use date and time formats that are appropriate for the region.
- When designing for speech, consider the environment conditions as well. Is it too noisy? Are there too many people?
- Notice how in the final transcript, we repeated information (the first 3 lines). This is important especially if the environment is crowded and noisy.
Get Attention → Deliver fact → Pause → Optionally repeat.
Now before we move to the next use case, we’ll learn some technicalities.
Computational Linguistics
Linguistics is the scientific study and analysis of human language. It involves different areas of research and branches — like phonetics, grammar and lexicography. The earliest person in history to have researched and documented this subject was Panini — an ancient grammarian and scholar from India, in the 6th and 5th century BC. Panini is considered in modern times as the father of linguistics.

With the advent of computers, and research and development in areas like machine learning and deep learning, it was inevitable that linguistics could be applied from a computational perspective too. This ultimately gave rise to computational linguistics and other interdisciplinary fields like natural language processing — which is why we have cool awesome gadgets like Amazon Alexa, and Google Home today!
Speech Recognition Models — Under the Hood
Speech recognition systems function by acoustic models and language models working in conjunction. Here’s a very nice read if you’d like to know the functions of some of these models.
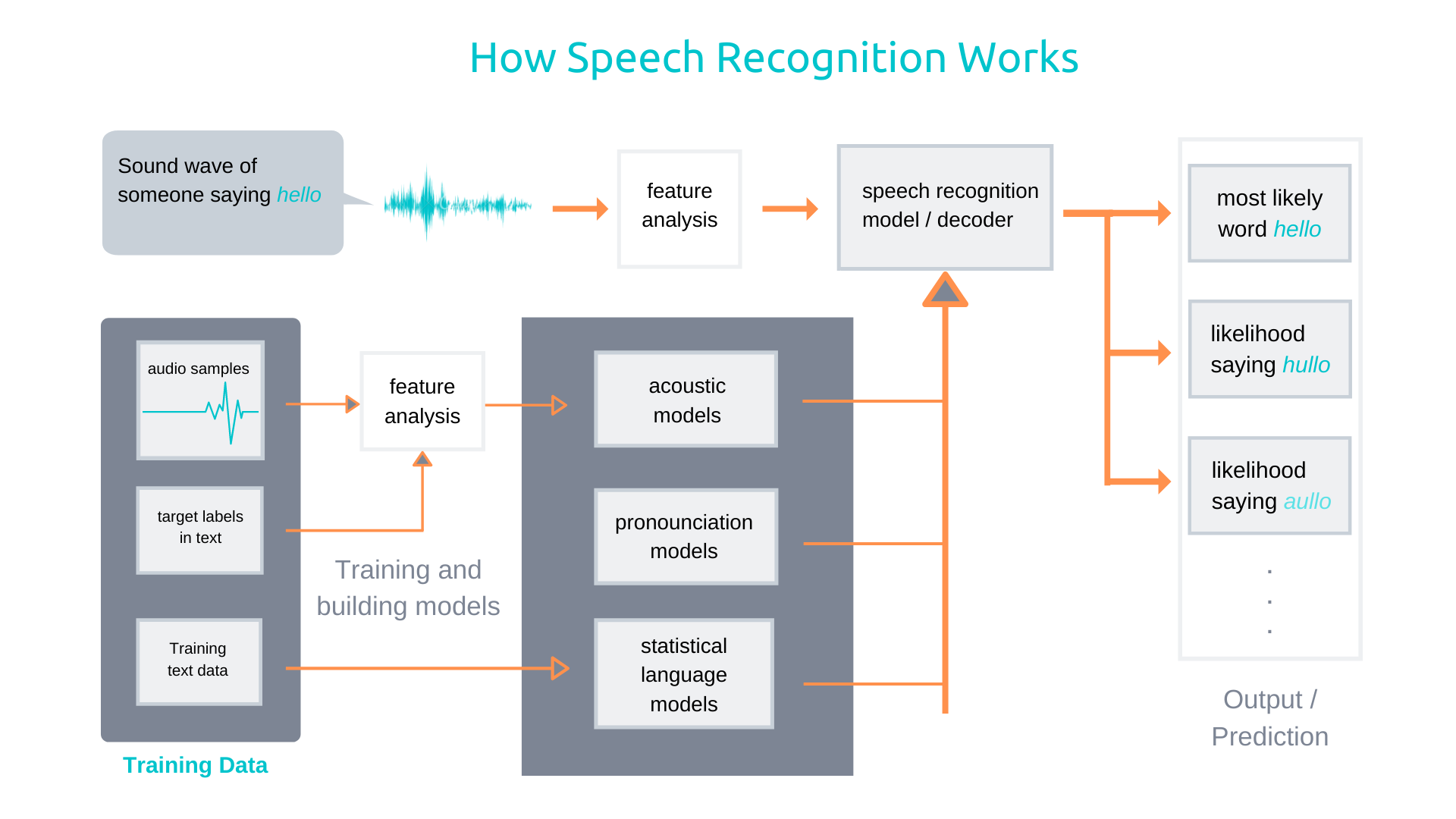
The latest speech recognition AIs are built using Recurrent Neural Networks — basically a neural network that has memory. When you say something, there is a close association between the words as you speak them one after the another to complete your sentence. So having memory helps the AI understand and make more accurate predictions in the future, based on what you spoke earlier.
I won’t get into the details of how the training works, but for now here’s what you need to know. During prediction, the decoder part of the AI makes several guesses, and spits out what it thinks is the most likely word that you said. Or, in mathematical terms — it outputs a range of probabilities.
You can also think of these probabilities as confidence scores — how confident is the system that you said a particular word. For example, if you say the word hello, the decoder could interpret it and give out these probabilities:
hello: 0.75, halo: 0.2, hullo: 0.05
In this case, the speech recognition system is very confident that you said the word hello, because hello has the highest probability score.
User Experience Use Case: Interactive Voice Response
Here’s another example from Bruce’s workshop that I’d like to illustrate —
App: What’s your number?
User: It’s two-zero-one… four-one-three… six-two-five-nine.
At this point the IVR’s speech recognition system would “guess” the word that the user most likely spoke, and assign probability scores. For the sake of simplicity, we’ll only take into account the first two best guesses for each number that the user spoke —
- two: 0.85, four: 0.15
- zero: 0.90, four: 0.10
- one: 0.80, seven: 0.20
- four: 0.98, zero: 0.02
- one: 0.90, seven: 0.10
- three: 0.99, six:0.01
- six: 0.9, nine:0.1
- two: 0.98, four:0.02
- five: 0.45, nine: 0.55,
- nine: 0.8, five: 0.2
Now, notice the 2nd digit from the last. The AI isn’t quite sure whether the user said the word five or the word nine. This could probably be because of the way the user pronounced the word, or maybe there was some noise introduced by the environment.
In such a scenario, the AI could prompt the user to confirm only the number which it isn’t sure about.
App: two-zero-one… four-one-three… six-two… nine-nine?
User: No, five-nine.
App: Five-nine. Got it.
See how clean and efficient that was? Confidence scores can be leveraged to a great advantage when designing what action or prompt that the system should make. You could, for example, set these thresholds —
- Greater than 0.8: Very confident. Just ask if the user wants to proceed.
- 0.5–0.8: Somewhat confident. Repeat and ask the user for a confirmation
- Less than 0.5: Not confident at all. Ask the user to repeat again what they said!
Great user experience is an outcome of design thinking interweaved with intelligence.
Here are some more examples that come to mind —
More examples
Booking a cab

Booking a hotel room

Paying bills
Here’s what you can do if you don’t get any input from the user

Conversational UX in Cinema
How many of us have wished that we had a wise-cracking, just a rather very intelligent system, like J.A.R.V.I.S from Marvel’s Iron Man? Or TARS from the movie Interstellar, having humour and trust settings —
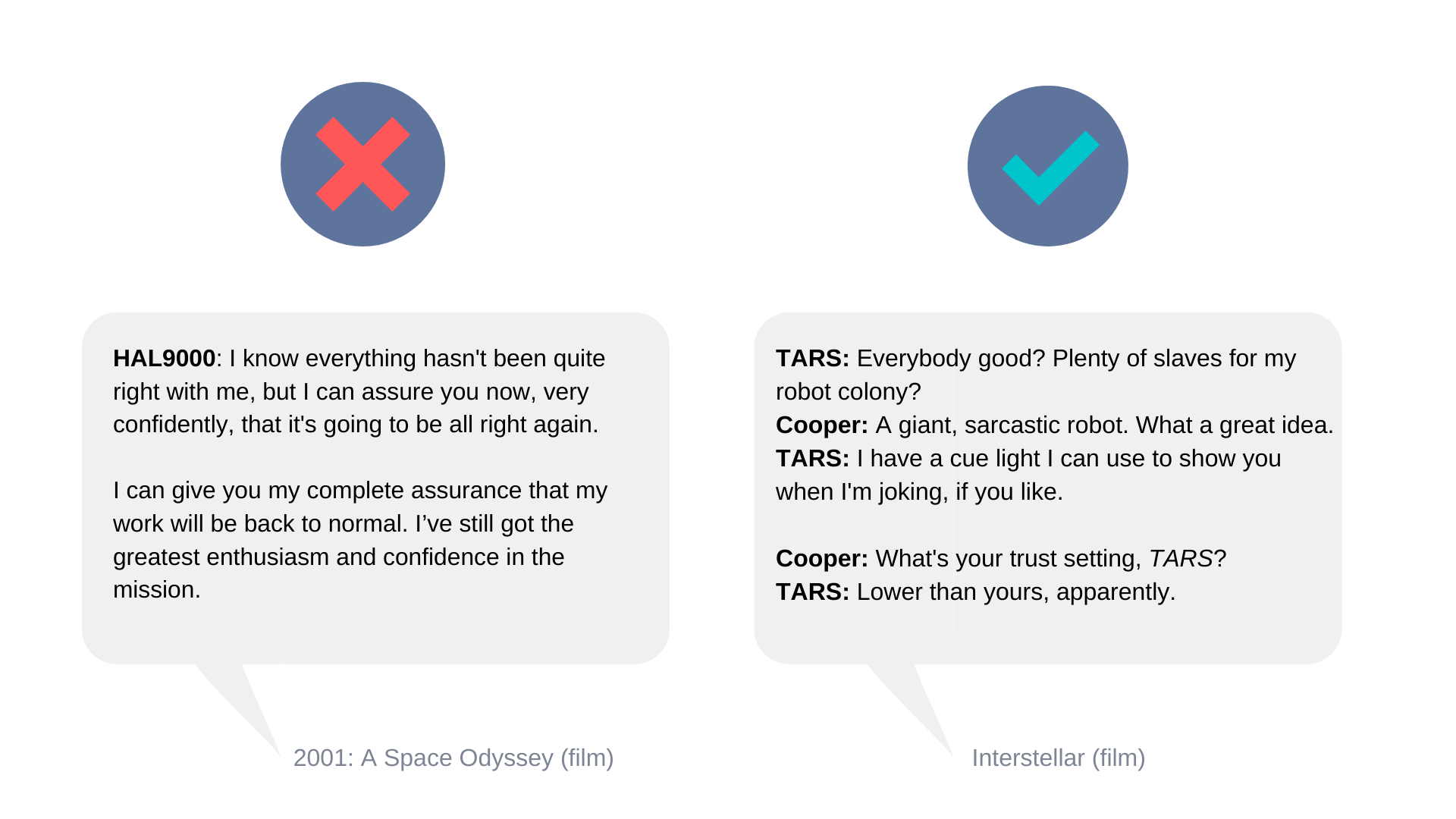
As humans, we tend to attribute and personify our human traits, emotions and intentions to non-human entities. This behaviour, called Anthropomorphism, is in our very nature and psychology. It’s for the same reason why we find TARS so interesting, because it sounds and responds very much like a human. It even has a personality of its own, being sarcastic and all — to the point where we don’t even think of it as a robot, but a person!
Using Anthropomorphism tactfully can create trust in users and positively affect the way they use a product or service, enhancing user experience.
“The urge for good design is the same as the urge to go on living. The assumption is that somewhere, hidden, is a better way of doing things” — Harry Bertoia, sound art sculptor.
What’s next?
Speech can be combined with other mediums, gestures, visual and tactile inputs to make for a truly awesome conversational user experience. Here are some fun exercises that I can think of right off the bat —
- Ordering food
- Searching on the web
- Looking for restaurants
- Asking for directions
- Surfing for shows
- Coaching a game
- Narrating the news
Resources
If you’re interested in learning more, here’s a list of great articles and resources —